前言
由于文档上云,前端在线预览word这一类的文件就成了刚需。为了满足这个需求,我们先看看有哪些技术能够帮助我们。
baseline
既然我们现在都要站在巨人的肩膀上了,那就干脆站一个最高的巨人。也就是说,我们直接用技术选型最贴合我们需求的、搭建起来最方便的应用,我们以后的工作都将从这个应用开始。
那么,无疑,这个应用就是Hexo了。简单的文件编写方式、多样化的文件样式、强大的静态资源管理,对小白来说上手超快。
文件在线预览
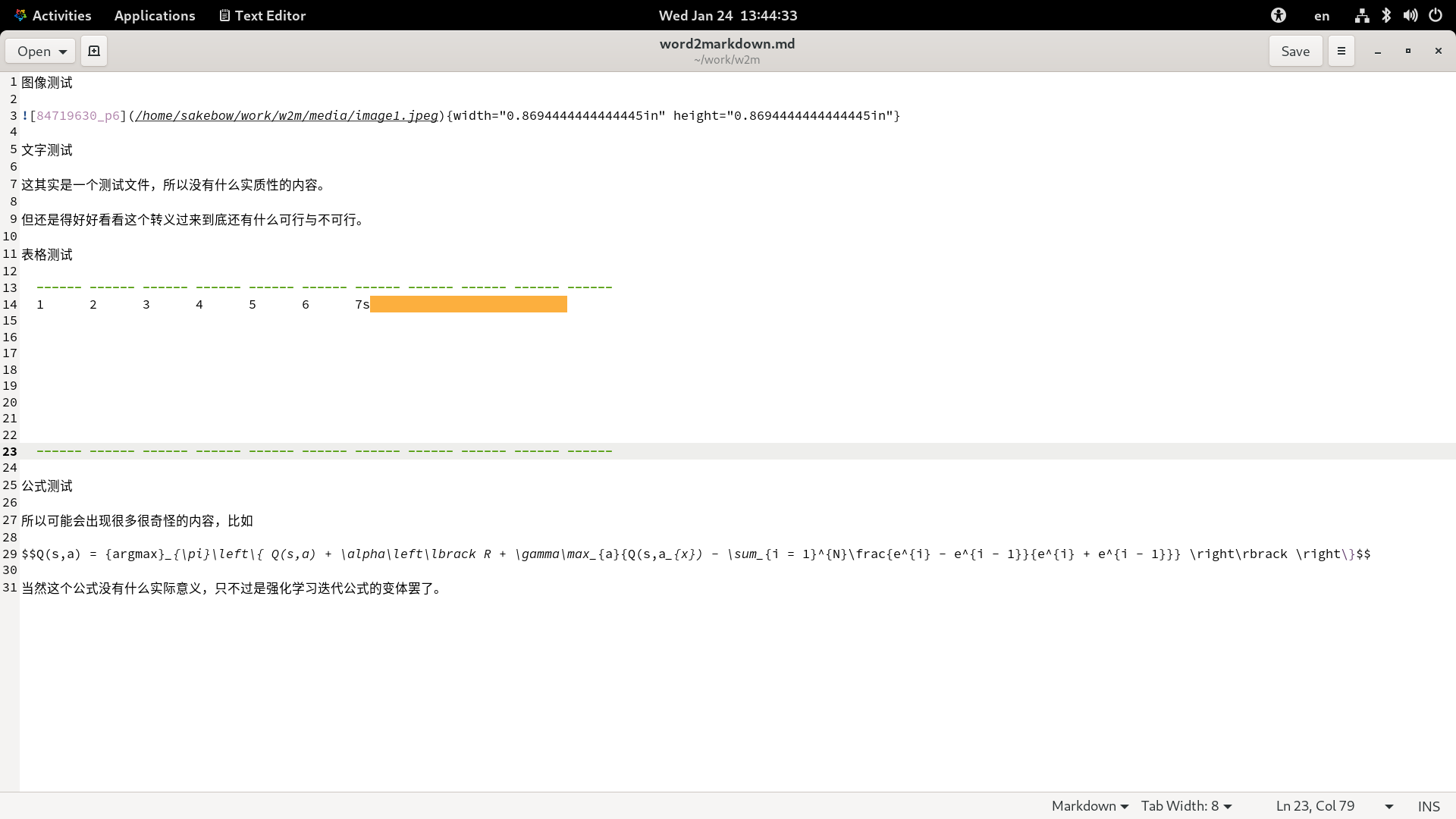
那么接下来就是正题了。如何实现文件预览呢?总之我们先准备一个文档,里面放入各种各样的内容,来检测是不是能好好的识别。
![准备文档]()
接下来,就来让我们介绍一下我们可以使用什么技术。
pandoc
既然是基于markdown的Hexo,那么就一定绕不过什么都转markdown的pandoc脚本。我们直接找到pandoc资源库,然后下载自己需要的内容。我这里选用pandoc-3.1.11.1-linux-amd64.tar.gz文件,然后解压,配置环境变量
配置环境变量主要是为了让pandoc无论在什么工作目录下都可以使用。
众所周知,markdown的图片功能完全是没有,所以在使用pandoc的时候别忘了把图片提取到单独的文件夹中,从而让markdown能够引用,也就是这个命令:
1
| pandoc -f docx -t markdown input.docx -o output.md --extract-media=$(pwd) --wrap=none
|
于是就生成了markdown文件与存放多媒体资源的media文件夹。
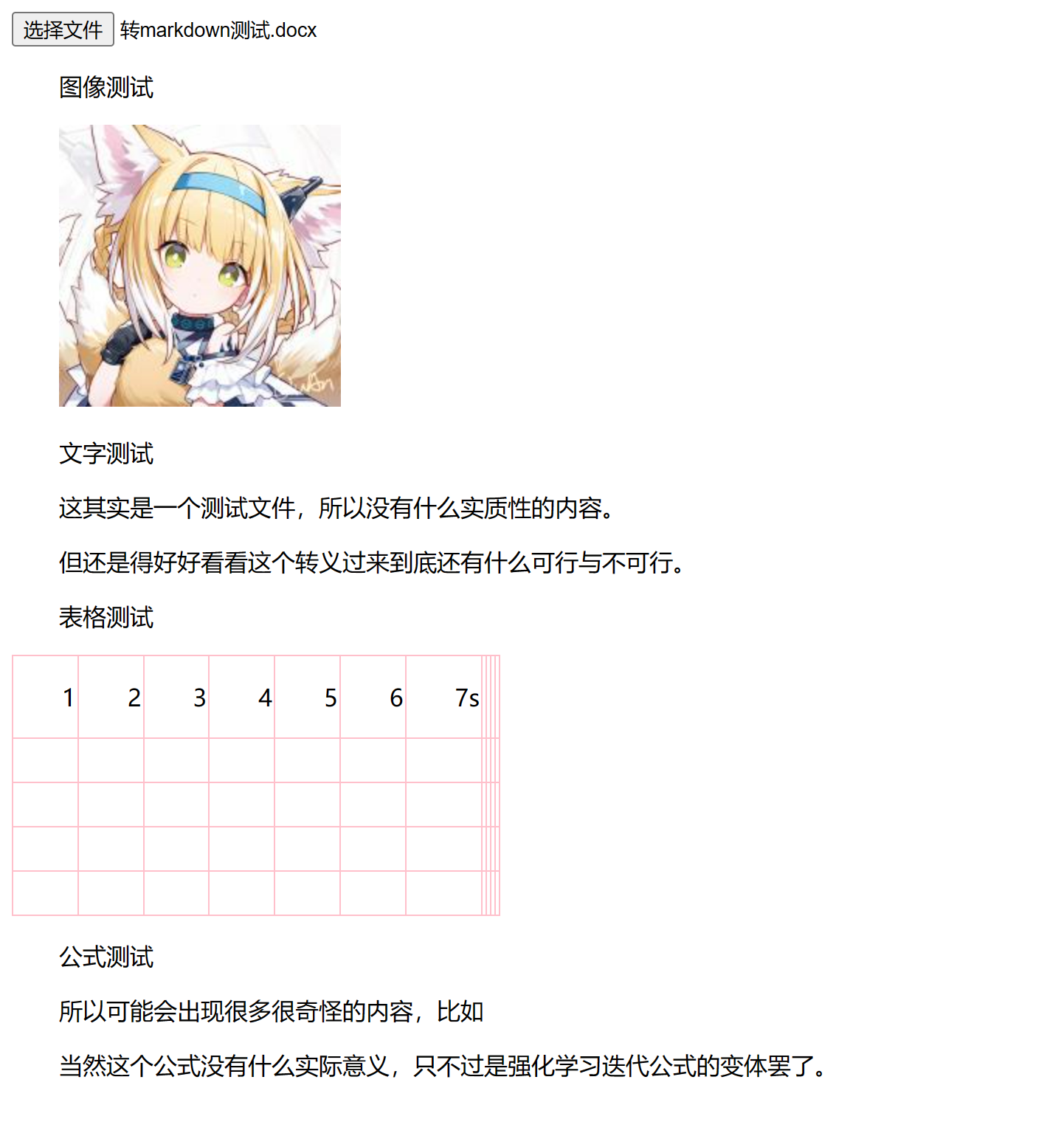
我们看看文件内容:
![pandoc执行结果]()
如果是自己用,那么这个结果已经可以说是很不错了,因为已经把很多字全都提取出来了。但是如果要形成产品,这还远远不够。
看来只能另想办法了。
mammoth.js
这是一个最简便的前端库了,开箱即用。
我们直接写一个本地提交文件的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| <!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>word预览</title>
</head>
<body>
<div>
<input id="document" type="file" />
<div style="width: 100%;">
<div>
<divclass="well"></div>
</div>
</div>
</div>
<script src="https://cdn.bootcss.com/mammoth/1.4.8/mammoth.browser.js"></script>
<script type="text/javascript">
document.getElementById("document").addEventListener("change", readFileInputEventAsArrayBuffer, false);
function displayResult(result) {
let html = result.value;
let newHTML = html.replace('<h1>', '<h1 style="text-align: center;">')
.replace(/<table>/g, '<table style="border-collapse: collapse;">')
.replace(/<tr>/g, '<tr style="height: 30px;">')
.replace(/<td>/g, '<td style="border: 1px solid pink;">')
.replace(/<p>/g, '<p style="text-indent: 2em;">');
document.getElementById("output").innerHTML = newHTML;
}
function readFileInputEventAsArrayBuffer(event) {
let file = event.target.files[0];
let reader = new FileReader();
reader.onload = function (loadEvent) {
const arrayBuffer = loadEvent.target.result;
mammoth.convertToHtml({ arrayBuffer: arrayBuffer }).then(displayResult).done();
};
reader.readAsArrayBuffer(file);
}
</script>
</body>
</html>
|
可以说是连样式都没有的简陋了。
那么效果又是如何呢?
![mammoth效果]()
比pandoc稍微好一点,好就好在表格识别出来了,也给了一定的样式。但也就仅此而已了。
vue-office
这相当于是另起炉灶的操作。先尝试一下试试。
首先,使用vue3创建一个vue项目,选用什么插件其实无所谓,默认配置也没什么不好的。
顺带着把需要准备的包也装上:
1
| $ npm install @vue-office/docx vue-demi element-plus --save --legacy-peer-deps
|
然后我们引入一个Element-plus,也就是在main.ts中写下这些:
1
2
3
4
5
6
7
8
9
| import { createApp } from 'vue'
import App from './App.vue'
import router from './router'
import ElementPlus from 'element-plus'
import 'element-plus/dist/index.css'
const app = createApp(App)
app.use(router).use(ElementPlus).mount('#app')
|
然后再在About.vue代码中的所有内容删掉,然后写下这些:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| <template>
<div id="docx-demo">
<el-upload :limit="1" :file-list="fileList" accept=".docx" :beforeUpload="beforeUpload" action="">
<el-button size="small" type="warning">点击上传</el-button>
</el-upload>
<vue-office-docx :src="src" />
</div>
</template>
<script lang="ts" setup>
import { ref } from 'vue'
import VueOfficeDocx from '@vue-office/docx'
import '@vue-office/docx/lib/index.css'
const src = ref()
const fileList = ref([])
function beforeUpload (file: Blob) {
const reader = new FileReader()
reader.readAsArrayBuffer(file)
reader.onload = (loadEvent) => {
let arrayBuffer = null
if (loadEvent.target) {
arrayBuffer = loadEvent.target.result
}
src.value = arrayBuffer
}
return false
}
</script>
|
官方文档给的是非typescript版本的,这里根据typescript的一些特点进行了一捏捏修改,并且大致上是符合typescript-eslint规范的。
试着运行一下:
出现了这样的结果:
![vue-office]()
这样的效果已经超出pandoc与mammoth太多太多了。
虽然说文本中使用的字体是黑体标题+宋体正文+英文Times New Roman,而在这里显示的只有微软雅黑的中文与Times New Roman的英文,公式的样式也是丑丑的,但是多少什么都能识别了。
当然,也有一定的局限性,比如页眉会被识别成正文、页脚页码会丢失。